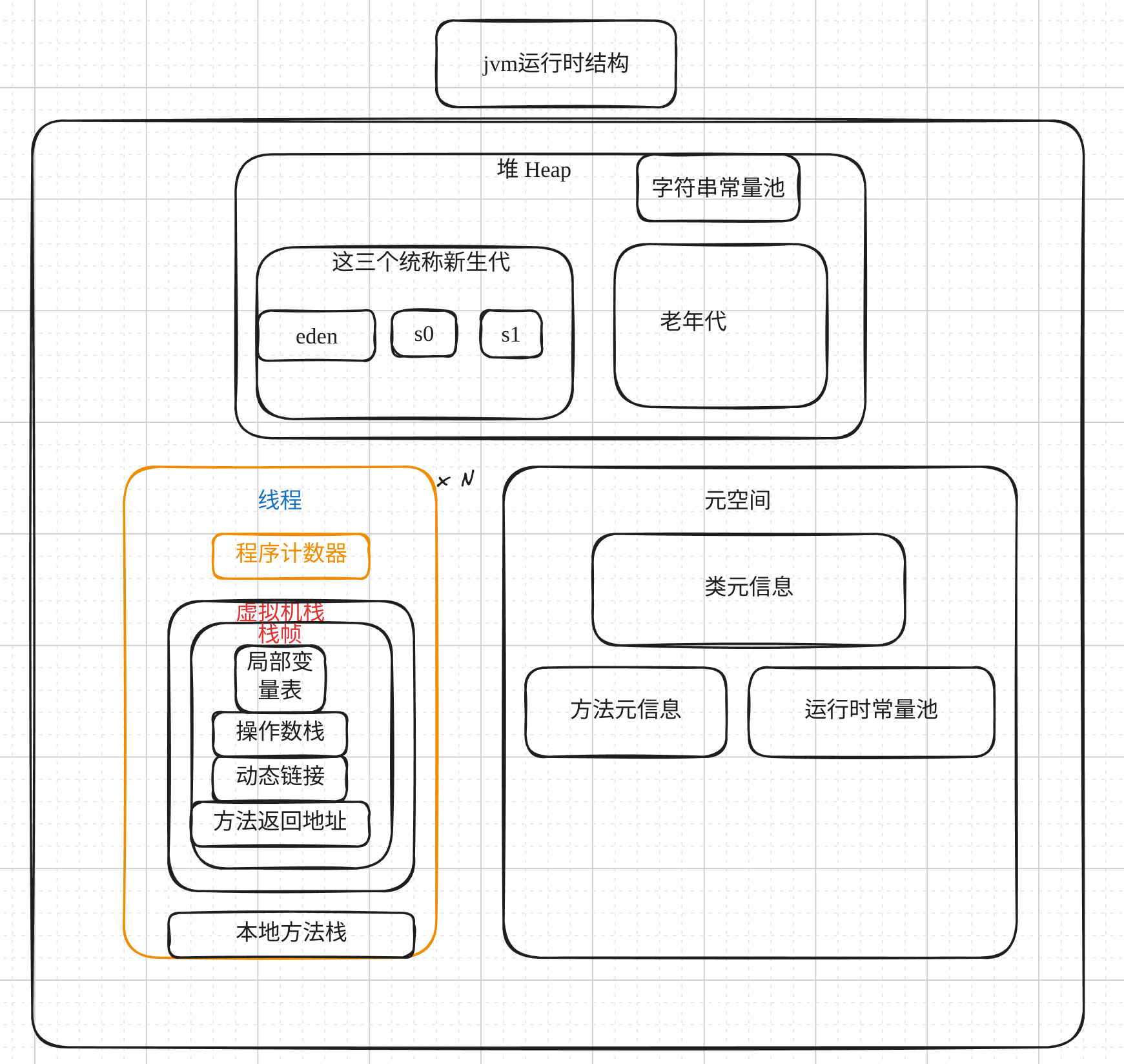
先看这张图:
一 运行时常量池
jvm从字节码中构建类信息,
先解析class文件中的字面量和符号引用到运行时常量池.
运行时常量池是每个类或接口在加载时创建的一个运行时数据结构,存储了编译期生成的各种字面量和符号引用。
字面量(Literals):
- 字符串常量(如 "Hello")。
- 数值常量(如 42 或 3.14)。
- 类型常量(如 true、false、null)。
符号引用(Symbolic References):
- 类的全限定名(如 java.lang.String)。
- 方法的名称和描述符(如 toString() 的方法签名)。
- 字段的名称和描述符(如 int x 的字段签名)。
运行时常量池为 JVM 提供了快速查找类、方法和字段的能力。
它是运行时解析符号引用的基础。
二 Class类元信息
类元信息是指与类本身相关的所有元数据,包括类的名称、父类、接口、字段、方法等。
类的全限定名:类的完整名称(如 java.lang.String)。
父类信息:类的父类(如 Object)。
接口信息:类实现的接口列表。
字段信息:类中定义的所有字段(包括名称、类型、访问修饰符等)。
方法信息:类中定义的所有方法(包括静态方法、实例方法等)。
访问修饰符:类的访问权限(如 public、abstract、final 等)。
注解信息:类上定义的注解(如 @Deprecated)。
类元信息为 JVM 提供了加载、链接和初始化类所需的全部信息。
它是 JVM 管理类生命周期的核心数据结构。
三 方法元信息
方法元信息是指与类的方法相关的所有元数据,包括方法的名称、参数类型、返回类型、访问修饰符等。
存储的内容:
方法名称:方法的名字(如 toString)。
参数类型:方法的参数列表及其类型。
返回类型:方法的返回值类型。
访问修饰符:方法的访问权限(如 public、private、protected)。
字节码:方法的实现代码(即方法体的字节码指令)。
异常表:方法可能抛出的异常列表。
方法元信息为 JVM 提供了执行方法所需的所有必要信息。
它是 JVM 解析和调用方法的基础。
> 说完这三个,其实metaspace就说完了.总结就是,存储了类的基本信息,包括类名,父类,接口,字段,方法(静态方法和实例方法),类中初始化的一些字面量等.
四 再说堆区
有了类,那么就要创建对象.
首先在eden中创建对象,大部分对象都在eden中创建,但是如果对象是大对象,直接进入老年代.
很多对象存活时间都很短,
当eden空间不够的时候会触发新生代GC(minor gc)时采用复制算法,将活着的对象复制到另一个survivor中.所以总有一个survicor是空的. 所以eden和两个survivor的比例是 8:1:1.
多次gc循环后活下来的对象会被移送到老年代中.
Minor GC时,Eden和From区向To区复制时,To区不够大,会直接把对象转移到老年代。
老年代中的对象生命周期较长,存活率比较高,在老年代中进行GC的频率相对而言较低,而且回收的速度也比较慢。
所以老年代要大一点.默认新生代和老年代的比例是 1:2.
四.1 堆区对象到底有什么
堆区用来存放对象实例!和数组!数组也是特殊的对象.
对象可分为{
1.对象头:{
存储对象的元数据信息:{
当前对象hash值
gc分代年龄
锁状态标识
线程持有的锁信息
}
类指针 class pointer:{}
}
2.实例数据:{
基本类型数据直接存这里
引用类型存引用地址
}
}> 到这里 堆也讲完了
五 类有了,对象有了,现在开始执行我们的程序了
jvm启动后找到main方法,启动主线程执行main方法 - main thread.(这时候就已经创建了线程对应的虚拟机栈和程序计数器\本地方法栈)
主线程是应用程序的起点,其他线程(如用户创建的线程或框架创建的线程)通常是基于主线程派生出来的.
执行main方法时会创建第一个栈帧,用来存储main方法的
栈帧结构:
局部变量
操作数栈,如在执行加法操作 x + y 时,x 和 y 的值会被压入操作数栈,然后弹出并计算结果。
动态链接,动态链接是一个指针,指向当前方法所属类的运行时常量池,用于解析符号引用。
方法返回地址,因为是main方法,所以没有返回值main方法栈压入main thread的虚拟机栈后,还会创建一个程序计数器,用来记录当前线程执行的字节码指令的行号.
如果有在当前线程继续调用其他方法,那么就会继续创建该方法的栈帧,并把栈帧压入虚拟机栈中.
如果启动了一个新的线程,那么就会创建该新线程对应的虚拟机栈\程序计数器. 还有本地方法栈用来执行native方法.
> OVER